Getting started with web scraping in Python
How to start scraping the web in Python, what tools to use, what's the approach and how to build strong apps based on it. I explain the approach I use when trying to scrap webpages

Every now and then a developer comes up with an idea, an app that would yield awesome results. The idea sounds pretty good, the plan theoretically sounds foolproof, however the developer gets stuck while developing the app because it's supposed to be dependent on another app, a famous app and the developer thought they would use the famous apps API. It seems the famous app doesn't have an API and if it has one, it allows limited access. The idea is dead.
If you do a simple Google search about Web Scraping, it'll lead you to the wiki page of Web Scraping, which notes that web scraping started way back in 1993. Even though back then, and even now, these scrapers were used to collect data from the sites, our aim would be a bit different. We don't want to collect all kinds of data but only the data that would benefit us.
I am not going to talk about the advantages of scraping the web or anything and neither am I encouraging anyone to scrap the web like anything. This will be just a simple tutorial focused on beginners who have just taken their baby steps in the world of Python and want to do something great. That doesn't mean this can't be referred by experienced people, just that they'll end up judging me as to why I am spoon feeding everything to the beginners.
For the sake of this article, we'll take the example of building a simple API for billboard that returns chart data based on the passed chart name.
The process can be broken down into 3 steps
Research can be considered the most important part. For the kind of scraper we are writing, it's really important to check the sources of the page and properly find div's that can be filtered out using their class names or id names.
It is assumed that basic knowledge of HTML is present in the reader. Most pages use div's to create sections except some pages like YouTube that use their own elements in HTML. However, once the understanding of elements is present, it becomes pretty straightforward.
So just fire up the URL you want to scrap on your preferred browser. I use Chrome for doing that but Firefox and Safari should behave similarly. Once the page is opened, open the developer tools by either the three dot menu on top right or by the Ctrl+Shift+I
Once the developer tools is open, go to the elements tab and start looking at the source code. It won't make much sense and by default all the outermost elements will be visible.
So browsers have this neat feature that if we hover the cursor on top of some element, the element lights up in the page.
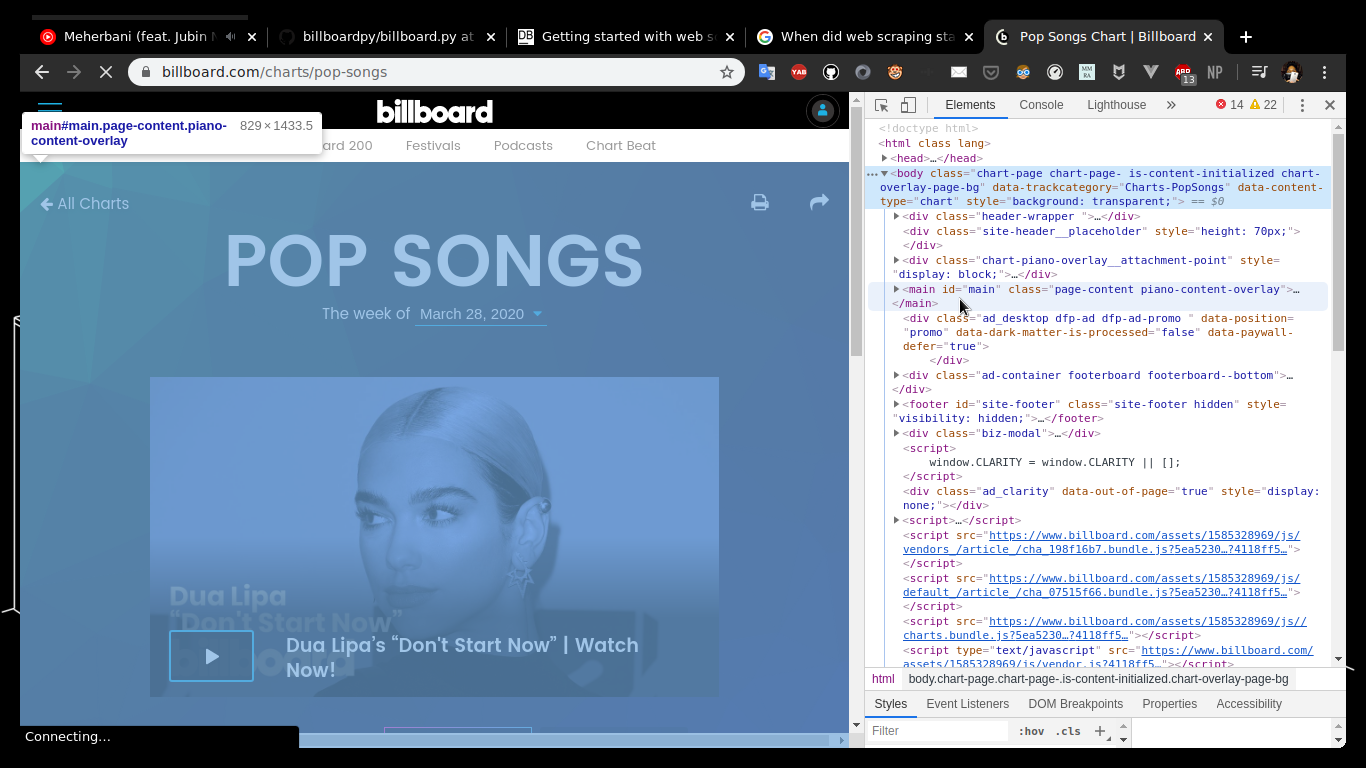 Element lights up on mouse hover
Element lights up on mouse hover
Once you figure out how to use this feature, dive into the code. Go to the part of the page, the data that you want from the page. After that start hovering on elements and get to the inner most element that actually contains the data.
Let's see which element contains the chart name.
So probably the element containing the chart name is somewhere inside the main element. Click on it and open it. Go through all the elements untill you find the element that's containing the chart name exactly. This is the element we are going to use to extract the name of the chart.
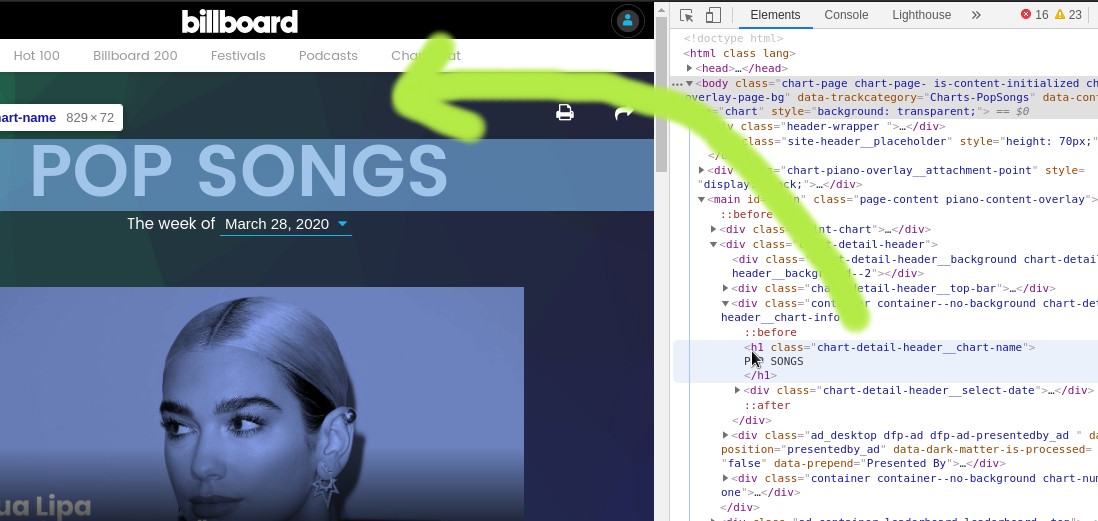
Now that we have the element containing the name of the chart, let's try to see if the class name of this element is unique.
We will use 3 tools to implement the scraper. There are a plethora of tools available to scrap webpages. Some tools are better than others and some are simpler than others. I like to go with the simple ones and so stick to these tools for eveything.
The tools I use are
We will need requests to get the page data. beautifulsoup4 or bs4 for formatting the data into something meaningful and regex or re to find out particular things from the data.
Once we have the tools installed, for all testing purposes rather than writing the script, open the python interpreter on Terminal by typing python. Once you are in Python, import all the modules.
After we have the modules, we will requests to make a get request and get the data and then pass the data ot BeautifulSoup to parse it. The process of extracting the exact data varies. I can't explain each and every step right now, take a look at the code below.
from requests import get # To get the page data
from bs4 import BeautifulSoup # To parse the data
import re # To extract certain things
url = "https://www.billboard.com/charts/pop-songs"
# Get the page data
response = get(url)
# Response is just an instance and the actual data
# is present in response.text or response.content
data = response.text
# Now pass the data to BeautifulSoup for it to parse it
soup = BeautifulSoup(data, "html.parser")
# The chart name is present in an h1 tag
# with the class chart-detail-header__chart-name
# We can use the findAll method of bs4 to find all the occurences
# of this class
temp_name = soup.findAll(
"h1",
attrs={"class": "chart-detail-header__chart-name"})
print("{} found".format(len(temp_name)))
print(temp_name)
Above script, when run outputs the following result.
# ------OUTPUT---------
# 1 found
# [<h1 class="chart-detail-header__chart-name">
# POP SONGS
# </h1>]
If we look closely, the output is a list with just one match which contains the h1 div we checked and it has the name of the chart inside the element.
Now, the problem we have is we need to extract the name from inside the element. How to do that? Yup, we will use regex to get the name.
First things first, if you check the output properly, you'll notice that after the 1 found line, there are 3 lines, which means there are \n in between them. Even if there won't be any, it's always good to try remove them.
re has all kinds of functions for this. We can use the sub() method for that.
If we look at the temp_name variable closely, we'll see that the name of the chart is present between > and (less than) / tags.
NOTE: I used less than above because HTML doesn't allow writing that tag without screwing up something.
So now, we can use a regex method to filter out anything that's between those two characters.
re.findall(r'img alt=".*?"', str(temp_name))
This will return a list containing all the matches of the above pattern.
After we get the above result, we'll some more patter matching to extract the final output. Look at the following code sample for that.
# This code should be written after the above code.
# We have the element containng the name in the
# temp_name variable.
# temp_name is currently a list containing all the
# matches, let's get the string out of it.
temp_name = temp_name[0]
# Replace all \n in the temp_name string
temp_name = re.sub("\n", "", str(temp_name))
# Once we have the string without any newline tags
# Try to match the pattern
#
# The name is between the > and </ chars
temp_name = re.findall(r'>.*?</', temp_name)
# Now we will have a list with the value
# ['>POP SONGS</']
print(temp_name)
# Need to remove those remaining tags now
name = re.sub(r'[></]', '', temp_name[0])
print("Chart name is: {}".format(name))
Above code will return the name after operating on it. Since the patter of each element containing the name will be same, we can use this logic for any chart URL passed.
Running the whole code, we get the following code.
# 1 found
# [<h1 class="chart-detail-header__chart-name">
# POP SONGS
# </h1>]
# ['>POP SONGS</']
# Chart name is: POP SONGS
So we have extracted the chart name. Now what? We can go on and try to extract song names as well from the chart.
This is probably a step that can be skipped but be ready to face some bugs. Especially if an API or a large code based app is being built then it's better not to skip this step.
It is about checking for those cases that might end up giving us errors. For eg: In some charts like the pop-songs chart, the first song is a large div and all the other ones are present in a list. So if we extract the list then we will skip the first song. Thus we need to make sure we look for all the possible cases.
There is no more to this step. It is a step that will take time to master considering the ability of a person to grasp things and so if the other two steps are understood, this is not really that important for beginners.
So that's it guys. I finally wrote a how to for web scraping. It's a powerfull skill. I have used it many of my projects, including some pretty large ones. It's also usefull when you don't want to look through a hell lot of API docs of apps like YouTube.
Also, for referral, the source code of my billboard API (simple one) can be found here.
Subscribe to get the latest posts. I mostly write about Backend (Python/MongoDB/Postgres), Frontend (Vue/Tailwind/SCSS) and Linux.


Discussion